
C++17 execution policy에 따른 성능 테스트
한 알고리즘 문제를 풀다가 std::all_of에 execution policy를 지정할 수 있다는 사실을 발견했다. 호기심이 발동했다. seq < par < par_unseq 순으로 빠르다는 것은 알고 있었지만 얼마나 빠를지 궁금했다.
알고리즘에서 std::all_of가 차지하는 부분은 굉장히 적었다. 그래서 나는 execution policy를 par_unseq으로 지정한다 한들 seq와의 유의미한 성능 차이가 발생할 거라고는 생각하지 않았다. 그러나 실험 결과는 예상 밖이었다. 굉장히 심한 성능 차이가 발생했기 때문이다. 그것도 안 좋은 쪽으로.
| 구성 | 실행 정책 | 수행 시간 (초) |
|---|---|---|
| debug | seq | 1.84 |
| debug | par | 2.69 |
| debug | par_unseq | 2.68 |
| release | seq | 0.04 |
| release | par | 0.44 |
| release | par_unseq | 0.43 |
당황스러웠다. 순차 실행보다 병렬 실행이 더 느리다니? 심지어 release 빌드에서는 차이가 무려 11배나 났다. 납득할만한 이유를 찾아야만 했다. 혹시 멀티스레드로 작동하지 않았나? 그래서 [](int i) {return i == 12; } 부분을 따로 함수로 빼서 중단점을 걸어봤다.
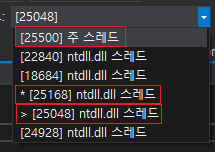
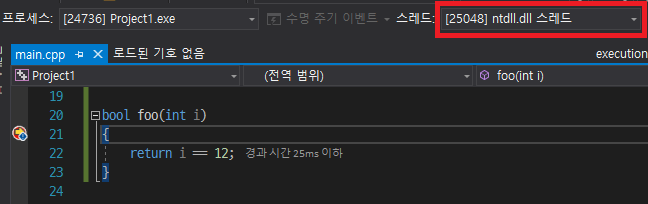
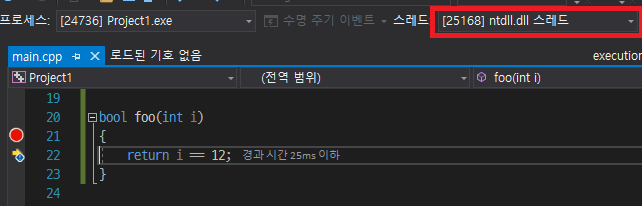
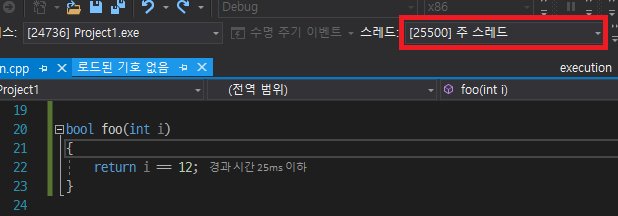
그러나 멀티스레드로 잘 작동하고 있었다. 그런데 대체 왜? 왜 느린 걸까?
이런 저런 고민을 해봤으나, 아마 나의 추측으로는 스레드가 무겁기 때문인 것 같다. MSVC의 execution 헤더에 있는 병렬 버전 std::all_of의 구현을 보면 (아래) std::all_of는 굉장히 간단한 알고리즘임에도 불구하고 굉장히 복잡한 것을 볼 수 있다.
// PARALLEL FUNCTION TEMPLATE all_of
template <bool _Invert, class _FwdIt, class _Pr>
struct _Static_partitioned_all_of_family2 { // all_of/any_of/none_of task scheduled on the system thread pool
_Static_partition_team<_Iter_diff_t<_FwdIt>> _Team;
_Static_partition_range<_FwdIt> _Basis;
_Pr _Pred;
_Cancellation_token _Cancel_token;
_Static_partitioned_all_of_family2(
_FwdIt _First, const size_t _Hw_threads, const _Iter_diff_t<_FwdIt> _Count, _Pr _Pred_)
: _Team{_Count, _Get_chunked_work_chunk_count(_Hw_threads, _Count)}, _Basis{}, _Pred(_Pred_), _Cancel_token{} {
_Basis._Populate(_Team, _First);
}
_Cancellation_status _Process_chunk() {
if (_Cancel_token._Is_canceled()) {
return _Cancellation_status::_Canceled;
}
const auto _Key = _Team._Get_next_key();
if (!_Key) {
return _Cancellation_status::_Canceled;
}
const auto _Range = _Basis._Get_chunk(_Key);
for (auto _First = _Range._First; _First != _Range._Last; ++_First) {
if (_Pred(*_First) ? _Invert : !_Invert) {
_Cancel_token._Cancel();
return _Cancellation_status::_Canceled;
}
}
return _Cancellation_status::_Running;
}
static void __stdcall _Threadpool_callback(
__std_PTP_CALLBACK_INSTANCE, void* const _Context, __std_PTP_WORK) noexcept {
_Run_available_chunked_work(*static_cast<_Static_partitioned_all_of_family2*>(_Context));
}
};
template <bool _Invert, class _FwdIt, class _Pr>
inline bool _All_of_family_parallel(_FwdIt _First, const _FwdIt _Last, _Pr _Pred) {
// test if all elements in [_First, _Last) satisfy _Pred (or !_Pred if _Invert is true) in parallel
const size_t _Hw_threads = __std_parallel_algorithms_hw_threads();
if (_Hw_threads > 1) { // parallelize on multiprocessor machines...
const auto _Count = _STD distance(_First, _Last);
if (_Count >= 2) { // ... with at least 2 elements
_TRY_BEGIN
_Static_partitioned_all_of_family2<_Invert, _FwdIt, _Pr> _Operation{_First, _Hw_threads, _Count, _Pred};
_Run_chunked_parallel_work(_Hw_threads, _Operation);
return !_Operation._Cancel_token._Is_canceled_relaxed();
_CATCH(const _Parallelism_resources_exhausted&)
// fall through to serial case below
_CATCH_END
}
}
for (; _First != _Last; ++_First) {
if (_Pred(*_First) ? _Invert : !_Invert) {
return false;
}
}
return true;
}
template <class _ExPo, class _FwdIt, class _Pr, _Enable_if_execution_policy_t<_ExPo> /* = 0 */>
_NODISCARD inline bool all_of(_ExPo&&, _FwdIt _First, _FwdIt _Last, _Pr _Pred) noexcept {
// test if all elements in [_First, _Last) satisfy _Pred with the indicated execution policy
_REQUIRE_PARALLEL_ITERATOR(_FwdIt);
_Adl_verify_range(_First, _Last);
auto _UFirst = _Get_unwrapped(_First);
const auto _ULast = _Get_unwrapped(_Last);
if constexpr (remove_reference_t<_ExPo>::_Parallelize) {
return _All_of_family_parallel<false>(_UFirst, _ULast, _Pass_fn(_Pred));
} else {
return _STD all_of(_UFirst, _ULast, _Pass_fn(_Pred));
}
}
이 코드들이 정확히 무슨 일을 하는지 자세히는 모르겠으나 대충 읽어보면 원소 각각에 대한 조건 연산을 여러 스레드에 적절히 분배하는 것 같다. (더 이상은 파고들어 해석해볼 엄두가 나지 않는다.)
요즘은 스레드 풀을 이용하여 스레드 생성/소멸 비용을 줄였다고 하지만, 여전히 스레드 스케줄링 비용은 무시할 수 없다. 때문에 굉장히 무거운 작업이나 백그라운드 작업과 같은, 오랫동안 수행되어 스레드의 활성화/비활성화가 자주 일어나지 않는 작업만이 멀티스레딩으로 성능상의 이득을 볼 수 있다는 사실을 알 수 있다.
그러나 위 알고리즘에서 병렬로 수행되는 작업은 너무나 단순하다. 그저 주어진 정수가 12인지 판별하는 게 전부다. 이렇게 간단한 작업을 굳이 병렬로 수행한다니, 심각한 스레드의 낭비가 아닐 수 없다. 뭐 원소가 10억 개 정도 된다면 모를까. 그래서 위의 표와 같은 결과가 나왔던 것이다. 이렇게 간단한 작업은 오히려 순차 실행이 빠르다는 말이다.
결론: 정말 특별한 경우가 아니라면, execution policy를 지정해줄 일은 거의 없다. 대부분의 경우 순차 실행으로 충분하며, 오히려 더 빠르기까지 하다.
다음에는 numeric_limits에 관해서 간단한 글을 써보겠다.
Comments